I gave a talk on R for the M.Sc. students at TERI University today. Here are some examples (PDF) I wrote up for the talk.
I was demonstrating ggplot2, and I showed them the plot below as an example of what not to do. This is a scatter plot of volatility in the Wholesale Price Index (WPI) for two years, but the result is cluttered by plotting all the 700 odd individual commodities but then tying the dot sizes and the transparency of the labels to the weight of the commodity in the WPI. The result gives an illusion of richness but conveys very little actual information.
Unfortunately we see more and more of plots of this type being put forward as examples of powerful data visualisation. I think a part of the reason for the popularity of complex data graphics is the visual appeal that comes from the appearance of depth that they give. Another reason is the well-meant desire to “let the data speak” without imposing an interpretation of one’s own. But to my mind this misses the point that the whole purpose of making a plot is to tell a story. If you want to just share the data the best way to do so would be in the form of a machine-readable file, not a set of pixels which are impossible to convert back into raw numbers.
As a counterpoint I showed the students this plot from Cleveland’s Visualizing Data. This is a plot of two years of data on barley yields for different varieties of barley at different experiment sites.
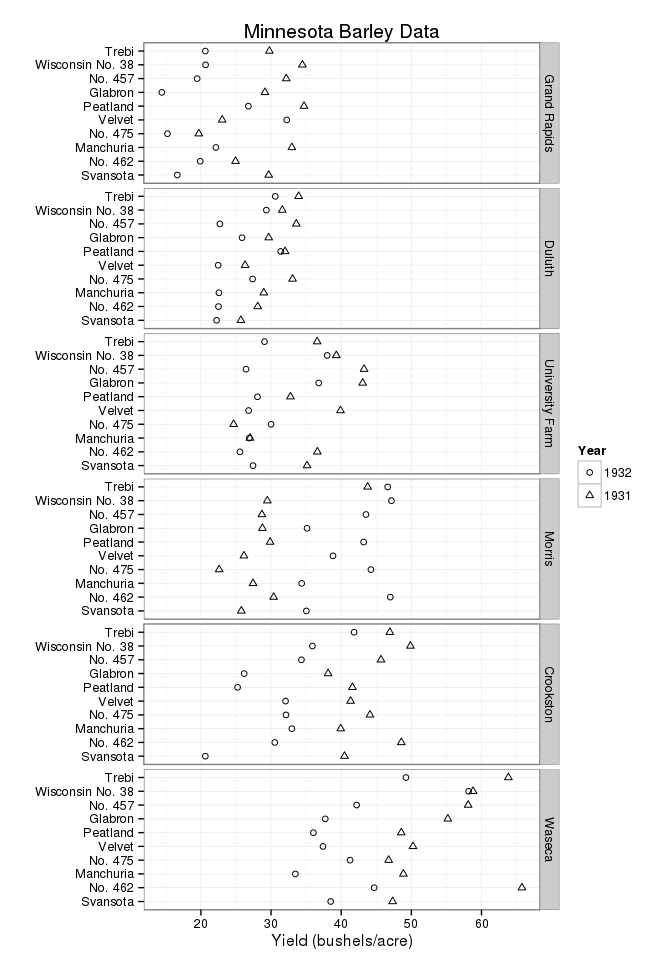
Cleveland discusses how this plot reveals an anomaly in the data that was missed by many statisticians who analysed the data set.
The comparison of the yield for the two years shows that it is only at the Morris site that the yield was higher in 1932 than in 1931. By itself this could be attributed to unobserved factor specific to Morris. But having a multipanel plot on a common scale allows us to easily compare the levels and changes across sites and see that though the Morris site has an opposite direction of change, the size of the change is about the same as at other sites. This makes an erroneous reversal of dates during data entry a more likely cause of the anomaly than idiosyncratic effects at Morris.
This is made even clearer by this box-and-whisker plot of the change in yields.
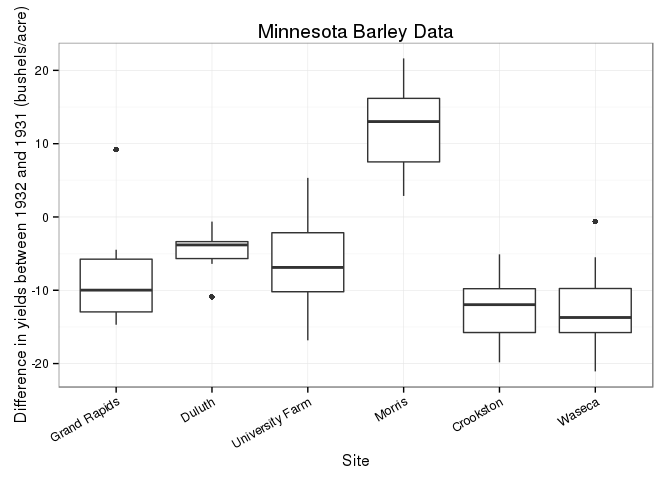
This plot also reveals another anomaly. There is an outlier for Grand Rapids with the “wrong” sign but a value close to the median. Looking at the previous graph shows that this is the observation for the Velvet variety. Perhaps, as Cleveland points out, though not on the basis of the same plot, this is another entry error.
I think economists make too little use of graphical devices such as faceted plots and boxplots. Statistics courses for economists end up devoting too much time to estimation and inference theory (some departments even claim to be teaching measure theory) and too little time to data exploration. As a result it seems to me that econometricians are falling behind the mainstream of statistics and data analysis. Changes to how econometrics is taught is the main way to correct this, but I think getting out of our Stata ghetto and sharing a tool like R with other data analysts will also help.
This is also the first time that I seriously used RStudio, and I must say that the support it provides for literate programming and interactive documents make me feel sorely tempted to shift away from Emacs+ESS.